Decision by Sampling, or ‘Psychologists Reclaim Their Turf’

Rethinking Economics, 2020
Pluralist Showcase
In the pluralist showcase series by Rethinking Economics, Cahal Moran explores non-mainstream ideas in economics and how they are useful for explaining, understanding and predicting things in economics.
![]()

Decision by Sampling, or ‘Psychologists Reclaim Their Turf’
By Cahal Moran
Economists like to base their theories on individual decision making. Individuals, the idea goes, have their own interests and preferences, and if we don’t include these in our theory we can’t be sure how people will react to changes in their economic circumstances and policy. While there may be social influences, in an important sense the buck stops with individuals. Understanding how individuals process information to come to decisions about their health, wealth and happiness is crucial. You can count me as someone who thinks that on the whole, this is quite a sensible view.
Naturally, psychologists are also interested in this area, but in terms of formal mathematical theories they’ve historically been one step behind. However, they are now catching up and in my view overtaking dominant economic theories. One advantage psychologists have is a plausible idea of how people actually make decisions, which in practice means the rules people follow in their theories have to be simple. Decision making is typically procedural, comparing different aspects of a problem one at a time rather than all together, and this means preferences are constructed rather than innate, taking time to arrive at and varying by context.
Decision by Sampling (DbS), pioneered by Neil Stewart, Nick Chater and Gordon Brown (no, not that one) is one of the best examples of constructed preferences. In this model peoples’ valuations - of, say, money – are based on ranking the amounts they usually receive from the highest to the lowest. So if you receive an amount of money much higher than what you are used to, you will value it highly; if you receive an amount much lower than you’re used to, you will value it less. While this may sound almost trivial, it is widely applicable and leads to some interesting predictions.
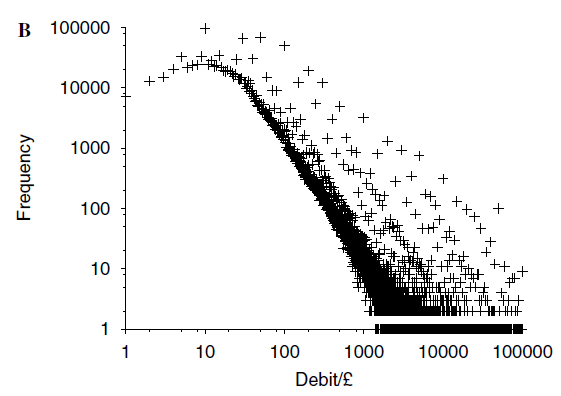
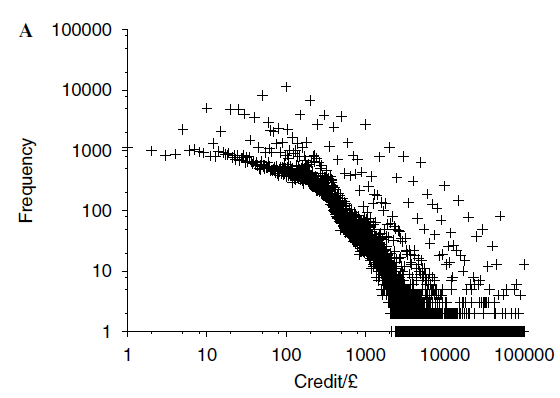
An everyday case is your bank balance. The data on credits to bank accounts exhibit something known as a ‘power law’, which is common in both the natural and social sciences. As shown by Figure A, what this means is that there are many small credits (think money owed/loaned by friends, refunds) whereas there are few large ones (such as a monthly salary). If you were to rank them all from the highest to the lowest, you’d find that the difference in ranking between a £10 and £20 credit was much higher than the increase between a £1000 and £1010 credit because your statement will contain many more between the former than the latter. What these means is that valuation of credits by DbS will exhibit the well-known property that people value the first £100 they get more than the next £100, which they in turn value more than the next £100, and so on – known as diminishing marginal utility.
Another common finding DbS predicts is ‘loss aversion’, a prominent idea where people value a loss around twice as highly as an equivalent gain. In DbS this is because small losses (or debits to your bank account) are much more frequent than small gains - we pay for food, bills and shopping much more often than we receive similar amounts, which is reflected in Figure B. Analogously to above, moving from -£10 to -£20 will entail a bigger move up the rankings than moving from +£10 to +£20, so the perceived value will change more quickly for losses. DbS thus predicts both diminishing marginal utility and loss aversion but for completely different reasons to usual: it’s not that these things are inherent to peoples’ valuation, but because of their typical experience. This means varying context can change valuations, which is something that the authors also verify using experiments. Most interestingly, they can make loss aversion disappear or even reverse. This is especially important given two recent papers have questioned how common loss aversion really is, since DbS may help us to understand when and why it will not be observed.
There are several other common findings that are predicted by DbS if we broaden its application and slightly tweak it. If we look at time instead of numbers – which may well use the same part of the brain – we can predict how people will value decisions which have consequences for the future. It is pretty well established that people tend to attach more value to the here and now than the far off, often called ‘discounting’ the future. As with bank credits/debits, people more often experience things which are going to happen relatively soon rather than far away, so they tend to ‘discount’ the further away things more highly. What’s more, as with valuations of money this creates a decay effect: the difference between tomorrow and next week is much bigger than the difference between a year from today and a year and a week from today. DbS can also be extended to risky decisions, but this makes things a bit more complicated and is beyond the scope of this blog post.
Decision by Sampling is a relatively new theory but it has started to be applied to a number of interesting problems. For example, it has been found that if people are ranked in terms of how much alcohol they drink, their relative rank predicts how they perceive health risks. In other words, if you are surrounded by alcoholics you are unlikely to think a couple of glasses of wine a night is a problem, but if you are surrounded by teetotallers you will. Similarly, peoples’ measured happiness (as done by surveys) depends on their relative rank within the income distribution instead of the absolute value or other plausible measures, something which lends support to the Spirit Level hypothesis that equality has a positive effect on peoples’ well-being as measured through various indicator.
As with any theory, DbS is not perfect. It struggles with decisions which can’t be ranked by one clear criteria: cars, for instance, differ in their size, speed, look, value for money, comfort, all in varying proportions – it is rare that one car will be universally better than all other options available at a similar price. There is also an issue of what determines the ‘sample’ of ‘decision by sampling’: how far do people reach back in their lives for monetary gains and losses? How quickly does the sample change with context? These things have to be determined before DbS can make predictions, otherwise it’s easy to pick and choose the sample to get the predictions you want, rendering the entire exercise a bit of a moot point. Nevertheless, DbS has achieved an impressive list of predictions using a simple and plausible framework, and I fully expect its range of useful applications to broaden in the future as we improve our understanding of constructed preferences.
There is still so much to discover!
In the Discover section we have collected hundreds of videos, texts and podcasts on economic topics. You can also suggest material yourself!
Discover material Suggest material